Topic 2, Contoso Ltd
Case study
This is a case study. Case studies are not timed separately. You can use as much exam time as you would like to complete each case. However, there may be additional case studies and sections on this exam. You must manage your time to ensure that you are able to complete all questions included on this exam in the time provided.
To answer the questions included in a case study, you will need to reference information that is provided in the case study. Case studies might contain exhibits and other resources that provide more information about the scenario that is described in the case study. Each question is independent of the other questions in this case study.
At the end of this case study, a review screen will appear. This screen allows you to review your answers and to make changes before you move to the next section of the exam. After you begin a new section, you cannot return to this section.
To start the case study
To display the first question in this case study, click the Next button. Use the buttons in the left pane to explore the content of the case study before you answer the questions. Clicking these buttons displays information such as business requirements, existing environment, and problem statements. If the case study has an All Information tab, note that the information displayed is identical to the information displayed on the subsequent tabs. When you are ready to answer a question, click the Question button to return to the question.
Overview
Existing Environment
Contoso, Ltd. is a financial data company that has 100 employees. The company delivers financial data to customers.
Active Directory
Contoso has a hybrid Azure Active Directory (Azure AD) deployment that syncs to on-premises Active Directory.
Database Environment
Contoso has SQL Server 2017 on Azure virtual machines shown in the following table.

SQL1 and SQL2 are in an Always On availability group and are actively queried. SQL3 runs jobs, provides historical data, and handles the delivery of data to customers.
The on-premises datacenter contains a PostgreSQL server that has a 50-TB database.
Current Business Model
Contoso uses Microsoft SQL Server Integration Services (SSIS) to create flat files for customers. The customers receive the files by using FTP.
Requirements
Planned Changes
Contoso plans to move to a model in which they deliver data to customer databases that run as platform as a service (PaaS) offerings. When a customer establishes a service agreement with Contoso, a separate resource group that contains an Azure SQL database will be provisioned for the customer. The database will have a complete copy of the financial data. The data to which each customer will have access will depend on the service agreement tier. The customers can change tiers by changing their service agreement.
The estimated size of each PaaS database is 1 TB.
Contoso plans to implement the following changes:
Move the PostgreSQL database to Azure Database for PostgreSQL during the next six months.
Upgrade SQL1, SQL2, and SQL3 to SQL Server 2019 during the next few months.
Start onboarding customers to the new PaaS solution within six months.
Business Goals
Contoso identifies the following business requirements:
Use built-in Azure features whenever possible.
Minimize development effort whenever possible.
Minimize the compute costs of the PaaS solutions.
Provide all the customers with their own copy of the database by using the PaaS solution. Provide the customers with different table and row access based on the customer’s service agreement.
In the event of an Azure regional outage, ensure that the customers can access the PaaS solution with minimal downtime. The solution must provide automatic failover.
Ensure that users of the PaaS solution can create their own database objects but he prevented from modifying any of the existing database objects supplied by Contoso.
Technical Requirements
Contoso identifies the following technical requirements:
Users of the PaaS solution must be able to sign in by using their own corporate Azure AD credentials or have Azure AD credentials supplied to them by Contoso. The solution must avoid using the internal Azure AD of Contoso to minimize guest users.
All customers must have their own resource group, Azure SQL server, and Azure SQL database. The deployment of resources for each customer must be done in a consistent fashion.
Users must be able to review the queries issued against the PaaS databases and identify any new objects created.
Downtime during the PostgreSQL database migration must be minimized.
Monitoring Requirements
Contoso identifies the following monitoring requirements:
Notify administrators when a PaaS database has a higher than average CPU usage.
Use a single dashboard to review security and audit data for all the PaaS databases.
Use a single dashboard to monitor query performance and bottlenecks across all the PaaS databases.
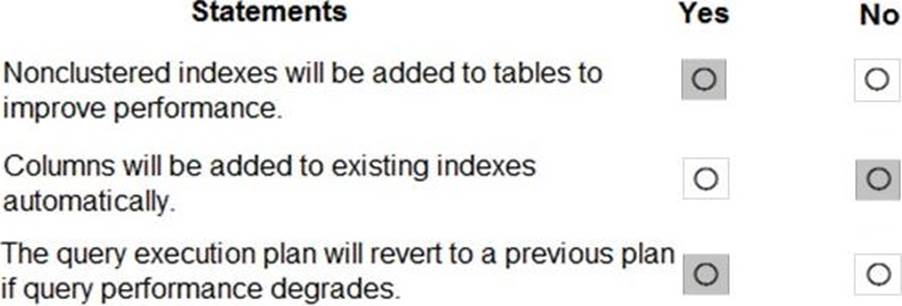
Monitor the PaaS databases to identify poorly performing queries and resolve query performance issues automatically whenever possible.
PaaS Prototype
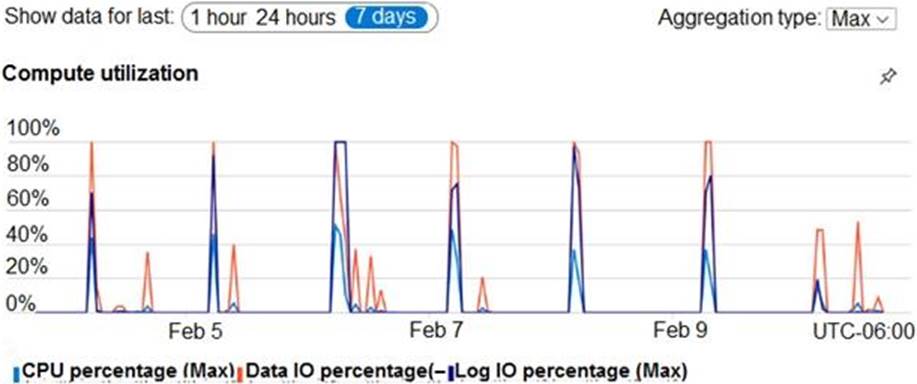
During prototyping of the PaaS solution in Azure, you record the compute utilization of a customer’s Azure SQL database as shown in the following exhibit.
Role Assignments
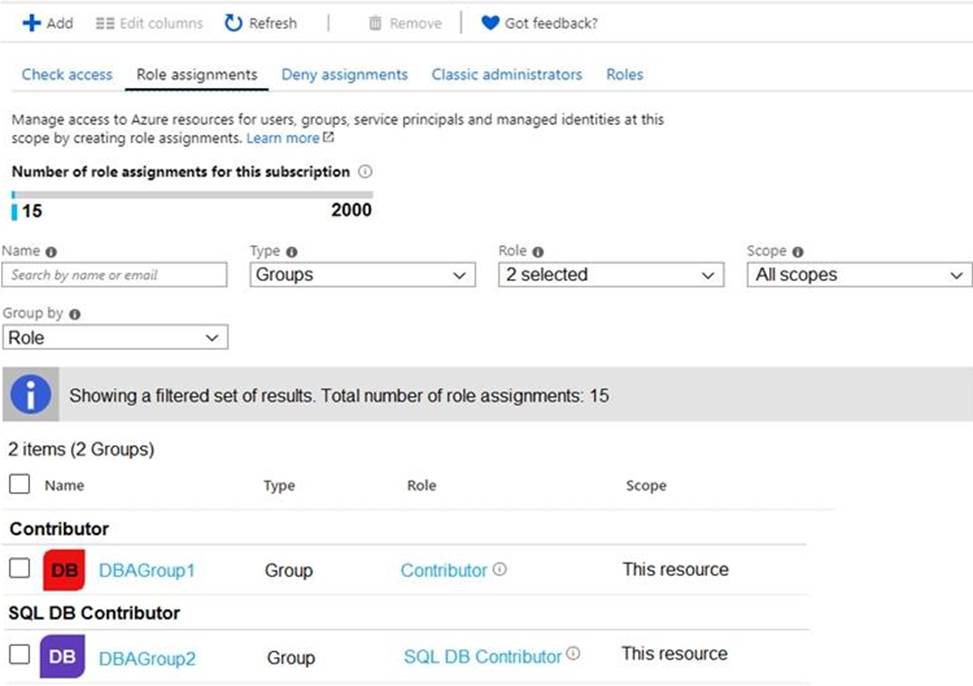
For each customer’s Azure SQL Database server, you plan to assign the roles shown in the following exhibit.
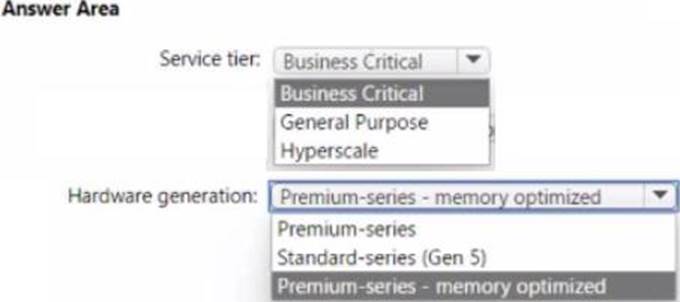
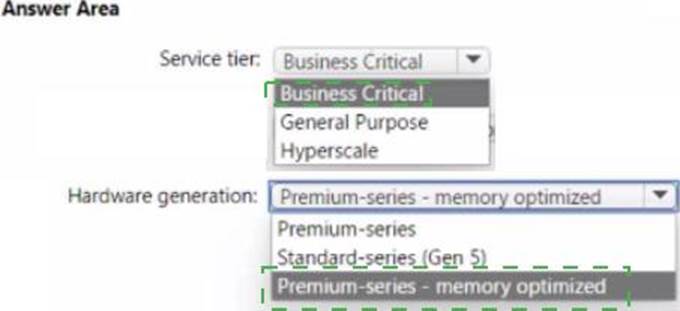
Based on the PaaS prototype, which Azure SQL Database compute tier should you use?