1. Topic 1, Litware
Existing Environment
Network Environment
The manufacturing and research datacenters connect to the primary datacenter by using a VPN.
The primary datacenter has an ExpressRoute connection that uses both Microsoft peering and private peering. The private peering connects to an Azure virtual network named HubVNet.
Identity Environment
Litware has a hybrid Azure Active Directory (Azure AD) deployment that uses a domain named litwareinc.com. All Azure subscriptions are associated to the litwareinc.com Azure AD tenant.
Database Environment
The sales department has the following database workload:
- An on-premises named SERVER1 hosts an instance of Microsoft SQL Server 2012 and two 1-TB databases.
- A logical server named SalesSrv01A contains a geo-replicated Azure SQL database named SalesSQLDb1. SalesSQLDb1 is in an elastic pool named SalesSQLDb1Pool. SalesSQLDb1 uses database firewall rules and contained database users.
- An application named SalesSQLDb1App1 uses SalesSQLDb1.
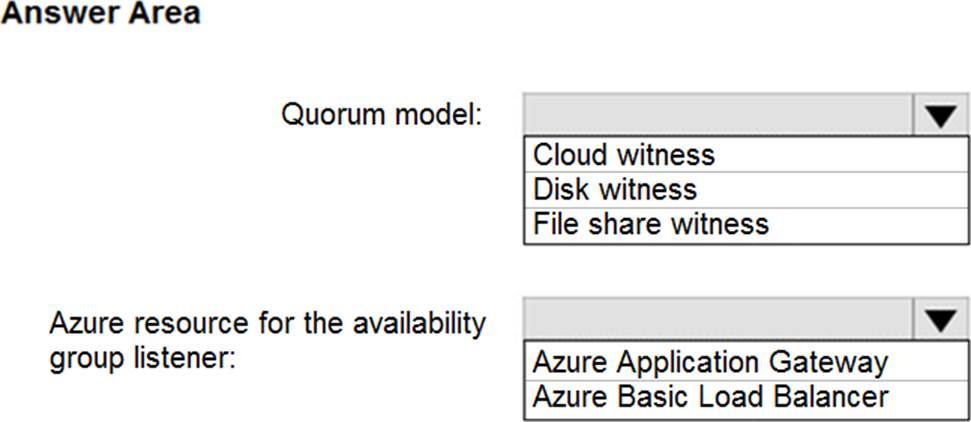
The manufacturing office contains two on-premises SQL Server 2016 servers named SERVER2 and SERVER3. The servers are nodes in the same Always On availability group. The availability group contains a database named ManufacturingSQLDb1
Database administrators have two Azure virtual machines in HubVnet named VM1 and VM2 that run Windows Server 2019 and are used to manage all the Azure databases.
Licensing Agreement
Litware is a Microsoft Volume Licensing customer that has License Mobility through Software Assurance.
Current Problems
SalesSQLDb1 experiences performance issues that are likely due to out-of-date statistics and frequent blocking queries.
Requirements
Planned Changes
Litware plans to implement the following changes:
- Implement 30 new databases in Azure, which will be used by time-sensitive manufacturing apps that have varying usage patterns. Each database will be approximately 20 GB.
- Create a new Azure SQL database named ResearchDB1 on a logical server named ResearchSrv01. ResearchDB1 will contain Personally Identifiable Information (PII) data.
- Develop an app named ResearchApp1 that will be used by the research department to populate and access ResearchDB1.
- Migrate ManufacturingSQLDb1 to the Azure virtual machine platform.
- Migrate the SERVER1 databases to the Azure SQL Database platform.
Technical Requirements
Litware identifies the following technical requirements:
- Maintenance tasks must be automated.
- The 30 new databases must scale automatically.
- The use of an on-premises infrastructure must be minimized.
- Azure Hybrid Use Benefits must be leveraged for Azure SQL Database deployments.
- All SQL Server and Azure SQL Database metrics related to CPU and storage usage and limits must be analyzed by using Azure built-in functionality.
Security and Compliance Requirements
Litware identifies the following security and compliance requirements:
- Store encryption keys in Azure Key Vault.
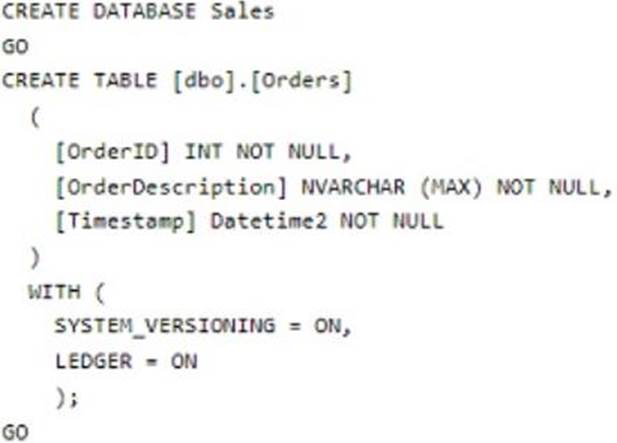
- Retain backups of the PII data for two months.
- Encrypt the PII data at rest, in transit, and in use.
- Use the principle of least privilege whenever possible.
- Authenticate database users by using Active Directory credentials.
- Protect Azure SQL Database instances by using database-level firewall rules.
- Ensure that all databases hosted in Azure are accessible from VM1 and VM2 without relying on public endpoints.
Business Requirements
Litware identifies the following business requirements:
- Meet an SLA of 99.99% availability for all Azure deployments.
- Minimize downtime during the migration of the SERVER1 databases.
- Use the Azure Hybrid Use Benefits when migrating workloads to Azure.
- Once all requirements are met, minimize costs whenever possible.
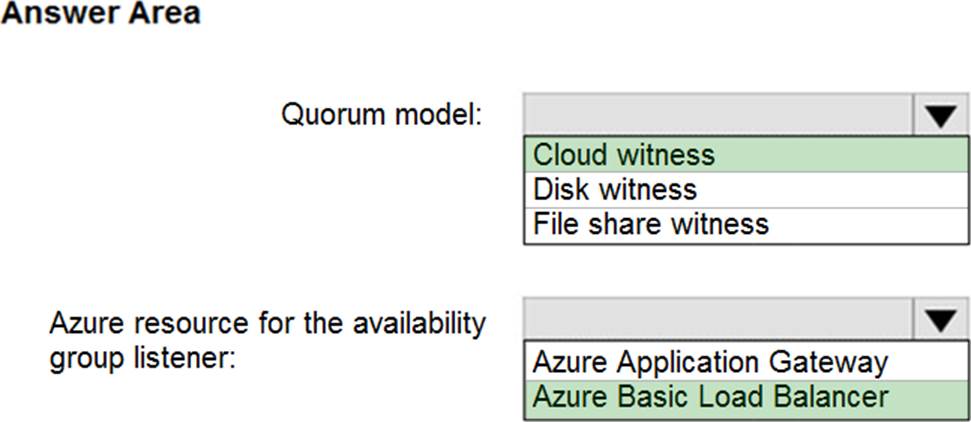
HOTSPOT
You need to recommend a configuration for ManufacturingSQLDb1 after the migration to Azure. The solution must meet the business requirements.
What should you include in the recommendation? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.